Google Analytics Customer Revenue Prediction -Kaggle challenge (Part One)
This time, I would try to use English to explain this whole project. I might make a lot of mistakes in grammar or words. If you detected anything wrong in these series posts. Please tell me. I sincerely want to improve my English skill.
Ok! Let’s start it! I took part in a competition in Kaggle. This competition is called Google Analytics Customer Revenue Prediction. This competition wants you to predict the revenue that consumers buy after they entered into the google merchandise website. When you entered into google merchandise store, Google would record everything you do on the website. Ex. visited, device.

Every competition has its own metrics. You have to achieve the highest/lowest score to win the champion. And this competition asks the participant to find the lowest rmse(root mean squared error). If you do not know how the rmse works, you could see the wiki. I scored the 1.4360, and ranked 949/2579
The general approach to a Kaggle competition is:
- Understand the problem and data descriptions
- Data cleaning/exploratory data analysis
- Feature engineering/feature selection
- Model optimization
- Interpretation of results
The series would have three posts to go through the whole project. This post would contain an understanding of the problem and data descriptions and Data cleaning/exploratory data analysis. You might think it is the easiest part of a data science project. But no. The data scientist usually should pay the most attention here. If you misunderstood the question and misload the dataset, problems would arise. What makes matters worse, it would waste your time to do the afterward process. So, getting ready and following my steps!
Understand the problem
As I say the problem above, the problem of this competition asked you to predict the revenue in a certain period and certain customers. In this competition, you have a total of 12 features and 1 target(revenue). If you saw the data set, you would discover some features that were dicts. In these dicts, the contents contain several features. So the whole features number would surpass sixty more. But don’t worry, I would handle it. And the metrics in this competition is rmse(root mean squared error)
First, I would import the libraries I would use in the future.
There are many libraries you would use in the project. Some libraries might not be used in a normal another project, but you must form a habit use these libraries. They are essential when you try to make the code clean and wonderful.
At the first, I do not know how to deal with the dict of the features, After I see an article in Kaggle, he gives the solution to the problem.
That is excellent to solve the tough question. Then we could start to preprocess the data. First, I inspect if the train set and test set have the same numbers of columns.
set(train_df.columns).difference(test_df.columns)
I would try to find what features are unique and the ratio of unique in every feature.
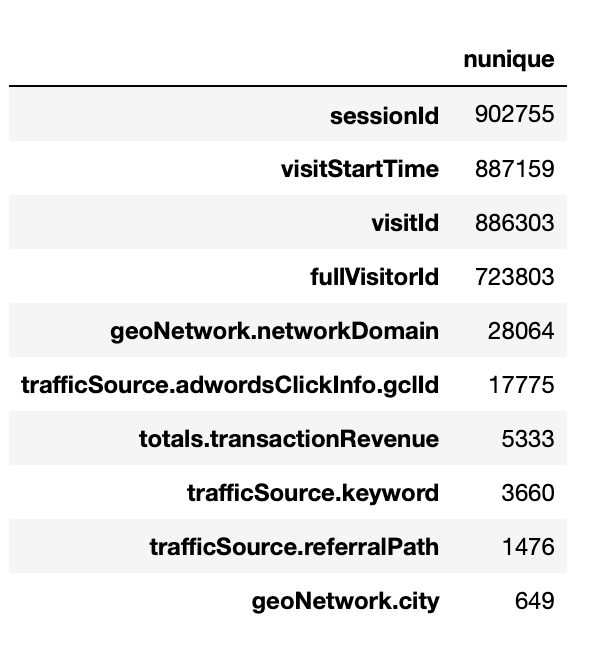
You could see these features that contain lots of unique categories. And then, The features that only have one category should be removed because they just have a category. We could distinguish how one category of features affects the target, so I would remove them.
drop=[i for i in train_df if train_df[i].nunique(dropna=False)==1]
The picture indicated what columns I would drop.
#'trafficSource.campaignCode' in train_df, not in test_df
train_df=train_df.drop(drop+['trafficSource.campaignCode'],axis=1)
test_df=test_df.drop(drop,axis=1)
gc.collect()Next, I came to deal with the missing data. Missing data makes machine learning hard to train the model. In this phase, I just see the ratio of missing data in the train and test set.
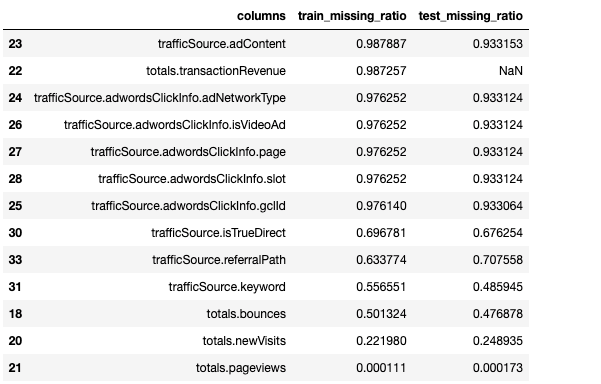
You could see the missing ratio of features and do nothing right now. The unique dataframe represents many features that have plenty of categories. Many features contain useless categories. Like ‘trafficSource.source’, the feature is consists of a lot of URL.
train_df[train_df['trafficSource.source'].str.contains('google')]['trafficSource.source'].value_counts()
You could see many ‘google’, but some ‘google’ could not make enough impact because they did not contain many quantities, so I try to merge all the categories that are less than 1000 in on features

I solve the problem that many features have useless categories.
Conclusion
It is happy to be here. I appreciated your read this article. I preprocess the data and make the important process before the deal with the feature engineering and feature selection. I am very excited that I wrote the first post in English. Thank you again!
I welcome feedback and criticism. You can reach out to me by sending the email to my email ychung38@asu.edu.